 |
| НАСА-гийн сансрын хөлөг хөөргөгчийн ШД-ын супер тооцоолол. Өндөр бүтээмжтэй тооцоолол (High performance computation) орчин үеийн тооцооллын өнгийг тодорхойлж байна. Ялангуяа шингэний динамикийг тооцон бодоход параллель тооцооллыг супер компьютер болон процессорын кластерийн тусламжтайгаар гүйцэтгэж байна. Масштаб өргөнтэй тооцооллууд болох уур амьсгалын загварчилал, хүрээлэн буй орчны загварчилал, гол мөрний гидравлик болон гидрологийн загварчилалыг өндөр нарийвчлалтайгаар богино хугацаанд үр ашигтай загварчилах хурдасгуур нь GPU эсвэл GPGPU байх боломжтой юм. |
График процессын нэгжтэй (GPU) танилцсан нь
GPU гэж юу вэ? График процессийн
нэгж (graphical processing unit) нь маш хурдтайгаар график, зургийг боловсруулж, бүтээж дэлгэцрүү гаргах зориулалттай онцгой
электрон хэлхээгээр зохион бүтээгдсэн процессорын нэгж юм. GPU-ийг супер компьютерээс эхлээд ухаалаг гар утасанд
хүртэл ашиглаж байна. Орчин үеийн GPU нь компьютер график/тоглоом болон зургийн боловсруулалтанд мөш өргөн
хүрээгээр, үр дүнтэй ажиллаж байна. Үүнээс гадна бидний зорьж байгаа тооцон
бодох ухаанд маш өргөн ашиглагдаж байгаа параллел тооцооллын хэрэгсэл юм. Одоо
зах зээл дээр байгаа GPU -ийн
ердийн бүтээгдэхүүнүүд нь
- NVIDIA GeForce
- AMD Radeon
- Intel HD Graphics нар юм байна.
Манай сургуульд (Nagaoka
University of technology) Fermi архитектуртай
Tesla M2050 процессор бүхий
кластер (процессоруудын
нэгдэл) байна. Энэ процессор
нь 448 кортой ба 14 дамжуулах мультпроцессортой (streaming
multiprocessor SM) юм байна. Нэг
дамжуулах мультпроцессор нь 32 кортой байдаг юм байна.
Үндсэн
үзүүлэлтүүд нь:
Куда кор (CUDA
core) дан нарийвчлал
|
448 кор
|
Куда кор давтамж
|
1,150Мгц (MHz)
|
Дан нарийвчлалд оргил
гүйцэтгэл
|
1.03ТераФлоп
(TFLOPS)
|
Давхар нарийвчлал дахь
арифметик нэгж
|
0*1 нэгж
|
Давхар нарийвчлалд оргил
гүйцэтгэл
|
515ГегаФлоп
(GFLOPS)
|
Санах ойн давтамж
|
1.55Ггц (GHz)
|
Санах ойн замын өргөн (bus)
|
348 бит
|
Санах ойн хамгийн их
бандийн өргөн (bandwidth)
|
148 Гбит/с (GB/s)
|
Кластар нь нийт
16 ширхэг Тесла М2050-иас бүрдэх ба нэг Тесла нь 4 ширхэг GPU тэй бөгөөд нийт 64 GPU процессор нь grouse хэмээх протокол сэлгэгч (gateway)серверээр холбогдоно. 
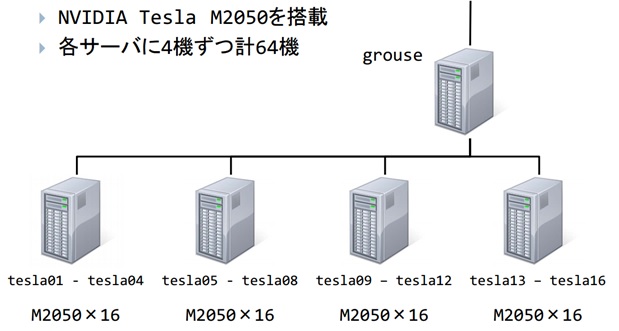
Гроус серверт
хэрхэн холбогдох тухай дараахаар тайлбарлана. Мэдээж зөвхөн энэ сургуулийн GPGPU
–д зориуслан нэвтрэх арга учир хаяг,
нууц үг өгөгдөх боломжгүй.
GPGPU-д нэвтрэх, ашиглах заавар
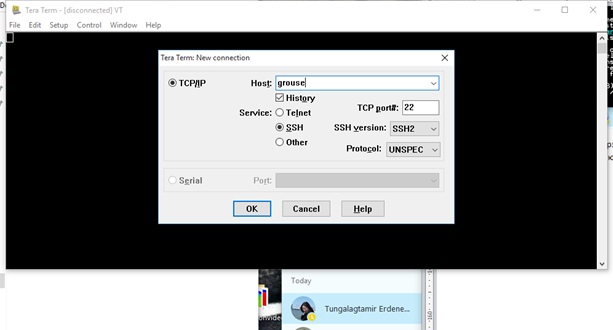
Tera Term програмыг
татаж аваад суулгана. Энэ програмын тусламжтайгаар GPGPU компьютерт холбогдоно. Суулгасаны дараа нээхэд
дараах цонх гарч ирнэ. Эхлээд яаж сургуулийн Линукс системд холбогдохыг үзье. Дараа нь GPGPU -дээ холбогдоё.

Энэ дээр host
гэдэг дээр nutech гэж бичээд ок дарж орвол сургуулийн LINUX сервэрт нэвтрэнэ. Энэ LINUX дээр програмаа бодуулж болно.

LINUX-д
холбогдохын тулд сургуулийн ID хаяг болон нууц үгээ хийж нэврэх шаардлагатай.

Энэ бол Линукс /LINUX/ үйлдлийн систем хэрэгтэй болсон үед
ашиглагдана. Хамгийн гол нь GPUGPU машинд хэрхэн холбогдох вэ гэдэг юм. Үүний тулд түрүүчийн host дээр grouse гэж бичнэ.

Энд ID болон нууц үгээ хийгээд орно.

Орсон эсэхээ
шалгахын тулд hostname гэж
бичнэ.

Энэ нь grouse-д холбогдсон байгааг илтгэнэ. Ингээд GPGPU дотор 01-16 хүртэл 16 ширхэг TESLA процессор холбоотой байгаа. Тэдгээрийн
нэглүү нь нэвтрэхдээ дараах маягийн код бичнэ.

Энд бид хамгийн
эхний tesla GPU руу нэвтрэх
гэж байна. коммандаа бичээд орох товчийг тогшсоны
дараа дараах сонголт гарч ирнэ.

Yes гэж бичээд
нэвтрэнэ. Тэгээд password хийх
шаардлагатай. Хийж байгаа password харагдахгүй болхоор маш анхааралтай бичих шаардлагатай.

Зан ингээд орсон
байна. Хэрэв tesla01 завгүй
бол бусадруу нь орох боломжтой. Эдгээрт өөрийн файлаа мөн байршуулах
шаардлагатай. Үүний тулд өөр програм суулгаж ашиглана. File transfer
Protocol төрлийн програм ашиглана. FFFtp
хэмээх япон програм ашиглаж болно.
Үүний англи хувилбар байвал бүр сайн.
Хэрэв тооцоо хийх
параллел бүтэцтэй програм байх юм бол с++ болон фортраны хөрвүүлэх комманд
ашиглан үйлдлийг гүйцэтгэх боломжтой. Жишээ нь с++ дээр хөрвүүлэхдээ
nvcc filename //
үүний араас хөрвүүлэх файл нь *.cu байх ба хөрвүүлэгдсэний дараа a.out байна.
тооцоогоо хийхдээ
яг Линукс шиг ./a.out гэнэ.
Харин Куда
фортран дээр
Pgfortran file name гэнэ.
За файлаа хэрхэн GROUSE
рүү шилжүүлэх талаар авч үзье. WinSCP
хэмээх програмыг дараах сайтнаас
татаж авч болно.
татаж аваад
суулгасаны дараа дараах цонх гарч ирнэ.

Үүн дээр hostname
дээр нь grouse гэж бичээд username and password дээр нь өөрийн ID болон нууц үгээ хийж нэвтрэнэ.

Иймэрхүү
анхааруулга гарч ирэх байх. Yes гэж дараад цааш нэвтрэнэ.

Эхний хагас нь
өөрийн чинь ком дээр байгаа файлын байрлал, харин хоёр дахь хагас нь grouse
дээрх файлуудыг харуулна. Гроус
сервэрт хадгалах санах ой байхгүй учир тусгай Hard drive дотор мэдээллийг хадгална. Энэ дискнээс бусад GPU тесла процессорлуу мэдээллийг илгээж буцааж авах
замаар солилцон ажиллана.
Д.Томохиро багшын сургалтын материалуудаас уншивал цаашдын хийх ёстой үйлдлүүд гарах болно.
Тесла (хэд) дээр хөрвүүлэх, тооцоо хийх
Хэд гэдэг нь хэддүгээр Тесла дээр тооцоолол хийх, түүнийг ашиглах вэ гэсэн үг юм. Линуксийн
коммандын мөр шиг ls гэвэл grouse
дотор байгаа миний файл хавтаснуудыг
харуулна.
Орох гэж байгаа
хавтасруугаа cd folder/ гэж бичиж орно. Харин фортран дээр хөрвүүлэх бол pgfortran
гээд файлын нэрээ өгнө. Үүний дараа
хөрвүүлэгдсэн файл нь a.out гэж
гарч ирнэ. Үүнийг бодуулахдаа ./a.out гэснээр бодуулах болно. Хэрвээ
байгаа фолдороосоо ухрамаар байвал Cd / эсвэл cd .. гэж бичнэ.
Харин бүр үндсэн фолдорлуугаа буцах бол cd ~ гээд орох товчийг дарна. Хаана байгаагаа мэдмээр
байвал pwd гэнэ. Present
working directory.
Куда фортран хэл
дээр бичигдсэн код бол *.cuf гэсэн өргөтгөлтэй байна. Дээр дурьдсанчлан энэ файлаа хөрвүүлсэний дараа
алдаа заахгүй бол биелэх файл a.out гэж гарч ирэх ба КУДА-тай холбоотой сонголттойгоор хөрвүүлэх бол –Mcuda=
… гэдгийг ашиглана.
Хэрэв хөрвүүлэх
ажиллагаан дээр PGI Fortran – ы сонголтуудыг болон мэдээллийг харах бол тусламжийг pgfortran –help
гэж болно. Эсвэл тодорхой хувилбар
дээрх сонголтуудыг хармаар байвал pgf90 –help гэх мэтээр үзэж болно.
GPU -ийн бүтэц
GPU нь дамжуулах
мультипроцессоруудын нэгдэл бүхий чипээс тогтох ба нэг дамжуулах мультипроцессор
нь Тесла М2050-ын хувьд 4 ширхэг КУДА короос тогтоно. Үндсэн дөрвөн төрлийн
санах ой байх ба тэдгээрийг багаас нь орчны (local), тогтмол (constant), текстур (texture), болон глобал (global) санах ой гэж нэрлэнэ. Эдгээрээс Глобал болон
орчны санах ойнууд нь орчны шинж чанартай байдаг.
КУДА гэдэг нь
төхөөрөмжийн архитектурыг нэгтгээд тооцоонд (Compute Unified Device
Architecture) хэрэглэх технологийг
хэлнэ.
КУДА Фортран, програмчилал
Куда фортран нь NVIDIA
GPU-д зориулсан стандарт фортран
хэлний өргөтгөл юм. Портланд грүпп (Portland Group эсвэл PGI гэнэ. Энэ грүпп фортран болон c++ хэлний өндөр хурдны тооцооллын кодуудыг хөрвүүлэгчдийг бүтээдэг) КУДА фортраны 10.0 – ээс хойших
хувилбарыг (2016 оны 1 сарын
7-ны байдлаар хамгийн сүүлчийн хувилбар нь 15.10) худалдаалж байна. КУДА Фортран шиг КУДА корт
зориулсан КУДА С болон КУДА С++ хэлнүүд мөн хэрэглэгдэж байна. Гэхдээ шинэ
хэрэглэгчийн хувьд КУДА Фортран нь бусдаасаа хялбар бөгөөд тооцооллын багтаамж
ихэсэх тусам тооцоолын хурд үлэмж буурдаг байна. Бага багтаамжтай, үйлдэлтэй
тооцооллыг КУДА С болон КУДА фортран дээр зэрэг ажиллуулахад С нь хурдан
хугацаанд гүйцэтгэдэг ч програмчлал нь төвөгтэй байдаг байна.
КУДА төрлийн
хэлээр програм бичихэд CPU нь
host, GPU нь device гэж нэрлэгдэх ба энэ зарчмаар хэрэглэгдэнэ. Хост
дээр програмын алгоритмын ерөнхий урсгал болон GPU хянагдах ба програмчлал стандарт фортан хэлтэй
ижил бичигдэнэ. Мөн GPU –г
дуудах, түүнээс мэдээлэл авах гэх мэт үйлдлүүд хост (CPU) дээр бичигдэж хостоор (CPU) хийгдэнэ.
Харин хэрэгсэл
дээр үйлдэмжүүд, функцууд, тооцоолол бичигдэх ба дэд програмын өмнө дуудлага
бичигдэж функц болон дэд програмыг цөм (kernel) гэж нэрлэнэ. Тэдгээрийн дуудлагыг хөөргөлт (call
-- launch) гэнэ.
Програмын ерөнхий
бүтцийг харахын тулд хялбар програм авч үзье.
1 2 3 4 | Program main Implicit none Print *, ‘hello world’ End program main |
Энэ програмын нэр
нь helloworld.f90 ба gfortran,
ifort эсвэл pgf90 дээр хөрвүүлэгдэнэ.
Дээрхи програмыг
КУДА фортранлуу шилжүүлбэл өргөтгөл нь *.cuf болно.
1 2 3 4 | Program main Implicit none Print *, ‘hello world’ End program main |
Нэрний өргөтгөл
өөрчлөгдсөнөөс биш кодонд ямар нэгэн өөрчлөлт ороогүй учир хөрвүүлэлт болон
тооцоололд хугацааны өөрчлөлт гарахгүй. Хөрвүүлэлтийн хувьд хост кодууд нь PGI
фортранаар хөрвүүлэгдэж харин
хэрэгсэлийн кодууд нь КУДА С-рүү хөрвүүлэгдэнэ. Ингээд хэрэгслийн кодуудыг
үндсэн кодруу шингээж өгье.
Download
time: 2062 microseconds ( 774 ms pinned)

 байна.
байна.
1 2 3 4 5 6 7 8 9 10 11 12 13 | Module cuf_kernel Implicit none Contains Attributes(global) subroutine kernel() ! GPU кернелээр тооцогдохын тулд тэмдэглэгээ ашиглана. End subroutine kernel End module cuf_kernel Program main use cudafor use cuf_kernel implicit none call kernel <<<1,1>>>() ! параллел тооцоололд шаардлагатай нэмэлт print *, ‘hello world’ end program |
Тухайлбал
тооцоолол хийхэд CPU анхны
утгуудыг өгөх, мэдээллийг хуулах, дамжуулах, кернелийг өгөх гэх мэтийг хийх бол GPU нь анхны утгуудыг ачаалах, мэдээллийг
хадгалах, кернелийг гүйцэтгэх, үр дүнг CPU рүү өгөх гэх мэт үйлдлийг хийнэ. Хэрэв CPU болон GPU хоорондын харилцааг зааж өгөөгүй бол хоорондоо
синхрон ажиллаж чадахгүй ба CPU үйлдлүүдийг гүйцэтгэх хэрэгтэй болно. Үүнийг дараах кодоор харуулъя.
Параллел
тооцоололд thread, block
хэмээхийг КУДА програмчлалд сайн
ойлгох хэрэгтэй.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | module cuf_kernel implicit none contains attributes(global) subroutine hello() ! Fermi-гээс дараагийн хувилбаруудад –Mcuda=cc20 сонголтоор хөрвүүлж болно. module cuf_kernel implicit none contains attributes(global) subroutine hello() print*,"gridDim'%'x",gridDim%x,"blockIdx'%'x",blockIdx%x,&"blockDim'%'x",blockDim%x,"threadIdx'%'x",threadIdx%x end subroutine hello end module cuf_kernel program main use cudafor use cuf_kernel implicit none integer :: stat call hello<<>>(1,1) ! кернелийн гүйцэтгэл stat = cudaThreadSynchronize()! хост болон хэрэгсэл хоорондын синхрон. Энэ заавал байх ёстой. end program main |
Энэ код нь
треад-ийг ойлгоход туслах ба програмын нэр нь hellothreds.cuf байна. Дээрх кодийг сонголттойгоор
хөрвүүлэхдээ
pgf90 ‐Mcuda=cc20 hellothread.cuf
Хашилтанд байгаа
тоог жишээ нь <<<2,4>>> болгоход 8 ширхэг үр дүнг гаргана. Тэгэхээр 2*4 удаа уг дуудагдсан кернел
ажилласан байна гэж үзэж болохоор байна.
-------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------
gridDim'%'x= 2 blockIdx'%'x= 1 blockDim'%'x= 4
threadIdx'%'x= 1 gridDim'%'x= 2 blockIdx'%'x= 1 blockDim'%'x= 4 threadIdx'%'x=
2 gridDim'%'x= 2 blockIdx'%'x= 1 blockDim'%'x= 4 threadIdx'%'x= 3 gridDim'%'x=
2 blockIdx'%'x= 1 blockDim'%'x= 4 threadIdx'%'x= 4 gridDim'%'x= 2 blockIdx'%'x=
2 blockDim'%'x= 4 threadIdx'%'x= 1 gridDim'%'x= 2 blockIdx'%'x= 2 blockDim'%'x=
4 threadIdx'%'x= 2 gridDim'%'x= 2 blockIdx'%'x= 2 blockDim'%'x= 4
threadIdx'%'x= 3 gridDim'%'x= 2 blockIdx'%'x= 2 blockDim'%'x= 4 threadIdx'%'x= 4
-------------------------------------------------------------------------------------------------------------------------
-------------------------------------------------------------------------------------------------------------------------
Энэ тоон өгөгдөл
параллел програмчлалын чухал зүйл гэдгийг дээр өгүүлсэн болхоор яаж энэ тоог
мэдэж өгөх вэ гэдэг асуудал урган гарч ирнэ. GPU-гийн хатуу диский бүтцээс уг тоо хамаарах ба
параллелизмын зэргийг илэрхийлнэ. GPU-ийн хатуу дискний (GPU бүтэц) бүтцийг бид дээр үзсэн ба хамгийн
бага нэгж нь КУДА кор гэсэн. Параллель тооцооллын гүйцэтгэгдэх
шатлалыг КУДА корын хувьд бичвэл Тор (grid) à Треад блок (Thread block) à
треад (thread) гэх гурав болно. Тор нь параллель тооцооллыг
хуваагдсан бүс бүсээр гүйцэтгэх ба треад нь CPU –ийнхтай ижижл бөгөөд GPU боловсруулалтын үндсэн нэгж болно. Эдгээр
шатлалуудад өөрийн гэсэн хэмжигдэхүүнүүд байх ба тухайлбал гурван хэмжээстэд x,y,z
гэсэн бүрэлдэхүүнд dim3 гэсэн функцын төрлийг эдгээр
хэмжигдэхүүнүүдэд хэрэглэнэ. Торны хувьд gridDim (торонд байх блокын тоо),
блокын хувьд blockIdx (хэвтээ чиглэл дахь блокын дугаар),
blockDim (блок дахь треадын тоо), треадын хувьд threadIdx (треадын дугаар) гэх мэт болно. Эдгээрийн утгыг жишээ нь тооцон
бодох бодлогийн хүрээг бодолцож өгөх боломжтой ба эдгээрийн байж болох хамгийн
их утгыг тухайн GPU-ийн
үзүүлэлт өгөх болно. Үүнийг мэдэхийн тулд хурдасгуурын мэдээлэл үзэх pgaccelinfo
гэсэн тушаалыг терминал дээр бичиж
өгнө.
Device
Number: 0
Device Name:
Tesla M2050
Device Revision Number:
2.0 !
хоёрдугаар үеийн GPU
Global Memory Size: 2817982464
Number of
Multiprocessors: 14
Number of
Cores: 448
Concurrent
Copy and Execution: Yes
Total
Constant Memory: 65536
Total Shared
Memory per Block: 49152
Registers
per Block: 32768
Warp Size: 32
Maximum Threads per
Block: 1024
Maximum Block
Dimensions: 1024, 1024, 64 !
бүх чиглэл дахь макс утга
Maximum Grid
Dimensions: 65535 x 65535 x 65535 ! блок дахь хамгийн их треадын тоо 1024
Maximum
Memory Pitch: 2147483647B
Texture
Alignment: 512B
Clock Rate:
1147 MHz
Initialization
time: 4222411 microseconds
Current free
memory: 2746736640
Upload time
(4MB): 2175 microseconds ( 829 ms pinned)
Upload
bandwidth: 1928 MB/sec (5059 MB/sec pinned)
Download
bandwidth: 2034 MB/sec (5418 MB/sec pinned)
Энгээд хаалтанд
байх хоёр тооны эхнийх нь блокийн тоо, удаах нь блок дахь треадын тоо болно. <<<блокын тоо, блок дахь треадын тоо>>>
Хийгдэх үйлдэл нь
блокын тоо*блок дахь треадын тоо=нийт треадын тоо байна.
Жишээ болгон
дараах хоёр векторуудын нийлбэр дахь комбинацуудыг авч үзье.
N=8, <<<2,4>>>


N=8, <<<1,8>>>

N=8, <<<4,2>>>

Хоёр векторын
нийлбэрийг CPU дээр цуваагаар
бичсэн кодыг авч үзье.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | module vectoradd_kernel implicit none integer,parameter :: N=2**20 contains subroutine add(a, b, c) implicit none real :: a(N) real :: b(N) real :: c(N) integer :: i do i=1,N c(i) = a(i) + b(i) end do end subroutine add end module vectoradd_kernel program main use vectoradd_kernel implicit none real,allocatable :: a(:) real,allocatable :: b(:) real,allocatable :: c(:) allocate(a(N)); a=1.0 allocate(b(N)); b=2.0 allocate(c(N)); c=0.0 call add(a,b,c) deallocate(a) deallocate(b) deallocate(c) end program main |
Энэ програм нь N=1048576
ширхэг а вектор дээр мөн тооны b
векторыг нэмэх програмыг фортран 90
дээр бичиж vectoradd_allocate.f90 гэж нэрлэжээ. Уг кодонд бусад хэлнүүдээс давуу комманд болон хувьсагчийн
эзлэх багтаамжыг тухайн үед нь зааж өгөх боломжтой allocate командыг ашигласан байна. Дээрх кодонд hello
world болон hello thread шиг КУДА фортраны нэмэлтүүдийг хийсэн ч
параллеллаар ажиллахгүй. Учир нь CPU болон GPU-ийн санах
ойнууд мэдээллээ шууд хуваалцах боломжгүй байна. Тиймээс хувьсагчийг GPU
дотор хадлгадах бол зарлах мөрөнд allocate-ийн араас device гэдгийг бичиж өгнө. Ингээд дээрх кодны 1 треадтай
КУДА Фортран хувилбарыг бичье.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | module vectoradd_kernel implicit none integer,parameter :: N=2**20 contains attributes(global)& subroutine add(a, b, c) implicit none real :: a(N) real :: b(N) real :: c(N) integer :: i do i=1,N c(i) = a(i) + b(i) end do end subroutine add end module vectoradd_kernel program main use vectoradd_kernel use cudafor implicit none real,allocatable,device :: a(:) real,allocatable,device :: b(:) real,allocatable,device :: c(:) allocate(a(N)); a=1.0 allocate(b(N)); b=2.0 allocate(c(N)); c=0.0 call add<<>>(a,b,c) deallocate(a) deallocate(b) deallocate(c) end program main |
Энэ кодны
өргөтгөлийг КУДА болгож vectoradd_1thread.cuf гэж өгье. Дээрх хоёр кодыг харьцуулж харвал attribute(global)
нь дэд програмын урд, use
cudafor нь үндсэн програмын зарлах
хэсэгт, device нь
хэмжигдэхүүнүүдийг зарлахад, <<<1,1>>> нь кернелийн дуудлагад кернелийн нэр болон
хурьсагч хоёрын голд нэмэгдсэн байна.
Энэ кодыг
хөрвүүлж тооцооллыг хийсний дараа цаг хугацааг тодорхойлох функц кодонд өгөөгүй
боловч export CUDA_PROFILE=1 коммандын тусламжтайгаар терминал дээр CPU, GPU хугацааг гаргах боломжтой.
Давталт нь 1-ээс
олон треад хэрэглэгдэж байвал треад болон блокын параметрүүдээр
тодорхойлогдоно. Тухайлбал N=8 давталт хийгдэх боловч дээрх комбинацаар ямар нэгэн хослол өгөгдөхөд кодыг
яаж бичих вэ гэхээр
1 2 3 4 5 6 7 8 | integer,parameter :: N=8 attributes(global) subroutine add(a, b, c) real :: a(N) real :: b(N) real :: c(N) integer :: i i = (blockIdx%x ‐1)*blockDim%x + threadIdx%x c(i) = a(i) + b(i) end subroutine add |
жишээний.
Бүрэн кодыг
бичвэл:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | module vectoradd_kernel implicit none integer,parameter :: N=2**20 contains attributes(global)& subroutine add(a, b, c) implicit none real :: a(N) real :: b(N) real :: c(N) integer :: i i = (blockIdx%x‐1)*blockDim%x& + threadIdx%x c(i) = a(i) + b(i) end subroutine add end module vectoradd_kernel program main use vectoradd_kernel use cudafor implicit none real,allocatable,device :: a(:) real,allocatable,device :: b(:) real,allocatable,device :: c(:) allocate(a(N)); a=1.0 allocate(b(N)); b=2.0 allocate(c(N)); c=0.0 call add<<>>(a,b,c) deallocate(a) deallocate(b) deallocate(c) end program main |
Нэрийг дурын өгч
болно. Гол нь өргөтгөл *.cuf байх ёстой.
Дээрх тооцооллын
гүйцэтгэлийг CPU болон
GPU гээр авч үзвэл
Боловсруулалт
|
Гүйцэтгэх хугацаа [милли сек]
|
CPU (1 треадтай)
|
4.55
|
GPU (1 треадтай)
|
206
|
GPU (256 треадтай)
|
0.115
|
Дээрхээс үзэхэд
хэрэв нэг треадтай бол GPU нь
CPU-гээс их хугацаа зарцуулж
үр ашиггүй ажиллахаар байна. Харин орон треадтай бол параллелизмын ачаар асар
бага хугацаанд үйлдлийг гүйцэтгэх нь байна.
Энд мөн C болон Фортраны гүйцэтгэлийн харьцуулалтыг
авч үзье.
Треадын/блокын тоо
|
Гүйцэтгэх хугацаа [милли сек]
|
|
С
|
Фортран
|
|
32
|
0.276
|
0.280
|
64
|
0.169
|
0.170
|
128
|
0.128
|
0.130
|
256
|
0.119
|
0.116
|
512
|
0.120
|
0.117
|
1024
|
0.151
|
|
Хоёр хэмжээстэй
векторыг нэмэх програмыг харьцуулж үзье.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | module vectoradd_kernel implicit none integer,parameter :: Nx=2**10 integer,parameter :: Ny=2**10 contains subroutine add(a, b, c) implicit none real :: a(Nx,Ny) real :: b(Nx,Ny) real :: c(Nx,Ny) integer :: i,j do j=1,Ny do i=1,Nx c(i,j) = a(i,j) + b(i,j) end do end do end subroutine add end module vectoradd_kernel program main use vectoradd_kernel implicit none real :: a(Nx,Ny) real :: b(Nx,Ny) real :: c(Nx,Ny) a=1.0 b=2.0 c=0.0 call add(a,b,c) print *,sum(c)/(Nx*Ny) end program main |
Дээрх бодлогийн
хүрээг параллелчилахын тулд блокуудад хувааж, блокоо треадуудад хуваана. Хоёр
хэмжээст учир х ба у чиглэлд блокуудыг зааж өгнө. Жишээ нь <<<dim3(2,4,1),dim3(4,2,1)>>>
гэвэл эхнийх нь треадын тоо болж
дараагийнх нь 1 блокод байх треадын тоог илтгэнэ. Харин нийт треадыг олохдоо
Nthread = Х
чиглэл дахь блокын тоо*нэг блок дахь треадын тоо*
У чиглэл дахь
блокын тоо*нэг блок дахь треадын тоо.
Нарийвчлавал Nx=8,
Ny=8 треадтай байна гэсэн үг. Х ба У
чиглэлд тус бүр 4 ширхэг блок, блок бүрд 2 ширхэг треад байна.


Блок болон
треадыг тогтоосоны дараа торны дугаарыг дараах томъёогоор тодорхойлж болно.
j=(blockIdx%y-1)*blockDim%y+threadIDx%y
КУДА фортраныг
авч үзвэл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | module vectoradd_kernel implicit none integer,parameter :: Nx=2**10 integer,parameter :: Ny=2**10 integer,parameter :: NTx=16 integer,parameter :: NTy=16 integer,parameter :: NBx=(Nx/NTx) integer,parameter :: NBy=(Ny/NTy) contains attributes(global) subroutine add(a, b, c) implicit none real :: a(Nx,Ny) real :: b(Nx,Ny) real :: c(Nx,Ny) integer :: i,j i=(blockIdx%x‐1)*blockDim%x+threadIdx%x j=(blockIdx%y‐1)*blockDim%y+threadIdx%y c(i,j) = a(i,j) + b(i,j) end subroutine add end module vectoradd_kernel program main use vectoradd_kernel use cudafor implicit none real,allocatable,device :: a(:,:) real,allocatable,device :: b(:,:) real,allocatable,device :: c(:,:) type(dim3) :: thread=dim3(NTx,NTy,1) type(dim3) :: block=dim3(NBx,NBy,1) allocate(a(Nx,Ny)); a=1.0 allocate(b(Nx,Ny)); b=2.0 allocate(c(Nx,Ny)); c=0.0 call add<<block,thread>>(a,b,c) deallocate(a) deallocate(b) deallocate(c) end program main |
ихэнхдээ х, болон
у дахь треадын тоог 32х8 эсвэл 256х1 гэсэн комбинацаар сонгох нь үр ашигтай
байдаг нь практикаар батлагдсан байна.
Хөндийн урсгалыг ЛБА-аар бодохдоо КУДА фортранаар параллелчилах
Хөндийн урсгалыг
хананд буцаж ойх, u хурдтай
хөдлөх хананд Зоу/Хе нарын хязгаарын нөхцлийг өгч өөр өөр х ба у хэмжээстэй үед
тооцон бодов. Цуваа код нь дараах гурван файлаас бүрдэнэ.
module_SimulationParameter.f90
|
Тооцонд өгөгдөх
параметрүүдийг агуулна. Сүүлийн үеийн фортран хэл нь модуль үүсгэж дэд
програмуудыг нэгтгэдэг болсон.
Энд хугацааны алхам,
Рейнольдсын тоо, Торны хэмжээ, зайн алхам, хананы хөдлөх ухрд, хугацааны
алхам, кинематик зунгааралт, тайвшралтын хугацаа зэргийг өгсөн байна.
|
module_D2Q9Model.f90
|
Энд бүх шаардлагатай дэд
програмуудыг оруулж өгсөн байна. Тухайлбал D2Q9-д хэрэглэгдэх тогтмолууд, тухайлсан хурднуудын
утгуудыг өгч, анхны нөхцөл өгөх, макро орчны хэмжигдэхүүн тодорхойлох, тэнцвэрт
түгэлтийн функц бодох, мөргөлдөөн тооцох, урсах алхам, хязгаарын нөхцөл өгөх
гэх мэт дэд програмууд байна.
|
lbm_cavity.f90
|
Энд гол програм бичигдсэн
байх ба програмын хувьсагчдын хэмжээг зааж зарлах, гол гүйцэтгэлийн гогцоог
оруулж өгсөн байна.
|
Кодууд.
module_SimulationParameter.f90 файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | module SimulationParameter implicit none integer,parameter :: Nt = 100 real(8),parameter :: Re = 1000d0 integer,parameter :: NumCell_x = 512 integer,parameter :: NumCell_y = NumCell_x integer,parameter :: Nx = NumCell_x integer,parameter :: Ny = NumCell_y real(8),parameter :: dx = 1d0/dble(NumCell_x) real(8),parameter :: Uwall = 0.5d0 real(8),parameter :: dt = Uwall*dx real(8),parameter :: KineticViscosity = Uwall/dx/Re real(8),parameter :: RelaxTime = 3d0*KineticViscosity + 0.5d0 real(8),parameter :: CoefRelax = 1d0/(3d0*KineticViscosity + 0.5d0) end module SimulationParameter |
module_D2Q9Model.f90 файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 | module D2Q9Model implicit none integer,parameter :: NumParticles = 9 integer,parameter :: Center = 0 integer,parameter :: Right = 1 integer,parameter :: Up = 2 integer,parameter :: Left = 3 integer,parameter :: Down = 4 integer,parameter :: UpRight = 5 integer,parameter :: UpLeft = 6 integer,parameter :: DownLeft = 7 integer,parameter :: DownRight = 8 integer,parameter :: First = Center integer,parameter :: Last = DownRight real(8),parameter :: Weight(First:Last) & =(/ 4d0/ 9d0, & 1d0/ 9d0, 1d0/ 9d0, 1d0/ 9d0, 1d0/ 9d0,& 1d0/36d0, 1d0/36d0, 1d0/36d0, 1d0/36d0 & /) integer,parameter :: ConvVelx(First:Last) = (/ 0, 1, 0,-1, 0, 1,-1,-1, 1 /) integer,parameter :: ConvVely(First:Last) = (/ 0, 0, 1, 0,-1, 1, 1,-1,-1 /) integer,parameter :: Opposite(First:Last) & = (/ Center,& Left, Down, Right, Up,& DownLeft, DownRight,UpRight,UpLeft/) contains !--- ! initialize macroscopic velocity and density !--- subroutine computeIntialMacroQuantities(velx,vely,dens) use SimulationParameter implicit none real(8),intent(inout) :: velx(Nx,Ny) real(8),intent(inout) :: vely(Nx,Ny) real(8),intent(inout) :: dens(Nx,Ny) integer :: i,j velx(:,:) = 0d0 vely(:,:) = 0d0 dens(:,:) = 1d0 velx(2:Nx-1,Ny) = Uwall end subroutine computeIntialMacroQuantities !--- ! compute macroscopic velocity and density from distribution function !--- subroutine computeMacroQuantities(f,velx,vely,dens) use SimulationParameter implicit none real(8),intent(in) :: f(First:Last,1:Nx,1:Ny) real(8),intent(inout) :: velx(1:Nx,1:Ny) real(8),intent(inout) :: vely(1:Nx,1:Ny) real(8),intent(inout) :: dens(1:Nx,1:Ny) integer :: i,j real(8) :: f_boundary, f_exterior do j=1,Ny do i=1,Nx dens(i,j) = f(Center ,i,j)& +f(Right ,i,j)& +f(Up ,i,j)& +f(Left ,i,j)& +f(Down ,i,j)& +f(UpRight ,i,j)& +f(UpLeft ,i,j)& +f(DownLeft ,i,j)& +f(DownRight,i,j) end do end do do i=2,Nx-1 f_boundary = f(Center,i,Ny)+f( Right,i,Ny)+f( Left,i,Ny) f_exterior = f(Up ,i,Ny)+f(UpRight,i,Ny)+f(UpLeft,i,Ny) dens(i,Ny) = f_boundary + 2d0*f_exterior end do do j=2,Ny-1 do i=2,Nx-1 velx(i,j) = ( f(Center ,i,j)*ConvVelx(Center )& +f(Right ,i,j)*ConvVelx(Right )& +f(Up ,i,j)*ConvVelx(Up )& +f(Left ,i,j)*ConvVelx(Left )& +f(Down ,i,j)*ConvVelx(Down )& +f(UpRight ,i,j)*ConvVelx(UpRight )& +f(UpLeft ,i,j)*ConvVelx(UpLeft )& +f(DownLeft ,i,j)*ConvVelx(DownLeft )& +f(DownRight,i,j)*ConvVelx(DownRight)& )/dens(i,j) vely(i,j) = ( f(Center ,i,j)*ConvVely(Center )& +f(Right ,i,j)*ConvVely(Right )& +f(Up ,i,j)*ConvVely(Up )& +f(Left ,i,j)*ConvVely(Left )& +f(Down ,i,j)*ConvVely(Down )& +f(UpRight ,i,j)*ConvVely(UpRight )& +f(UpLeft ,i,j)*ConvVely(UpLeft )& +f(DownLeft ,i,j)*ConvVely(DownLeft )& +f(DownRight,i,j)*ConvVely(DownRight)& )/dens(i,j) end do end do end subroutine computeMacroQuantities !--- ! compute local equilibrium distribution !--- subroutine computeLocalEquilibriumFunction(f_eq,velx,vely,dens) use SimulationParameter implicit none real(8),intent(inout) :: f_eq(First:Last,1:Nx,1:Ny) real(8),intent(in) :: velx(1:Nx,1:Ny) real(8),intent(in) :: vely(1:Nx,1:Ny) real(8),intent(in) :: dens(1:Nx,1:Ny) real(8) :: u,v,conv_velo,velo_square integer :: i,j,direction do j=1,Ny do i=1,Nx u = velx(i,j) v = vely(i,j) velo_square = u*u + v*v do direction = First,Last conv_velo = u*ConvVelx(direction)& + v*ConvVely(direction) f_eq(direction,i,j) = Weight(direction)*dens(i,j)& *(1d0 + 3d0*conv_velo + 4.5d0*conv_velo*conv_velo - 1.5d0*velo_square) end do end do end do end subroutine computeLocalEquilibriumFunction !--- ! collision step !--- subroutine collide(f,f_eq) use SimulationParameter implicit none real(8),intent(inout) :: f (First:Last,1:Nx,1:Ny) real(8),intent(in) :: f_eq(First:Last,1:Nx,1:Ny) integer :: i,j,direction do j=1,Ny do i=1,Nx f(:,i,j) = f(:,i,j) + (f_eq(:,i,j)-f(:,i,j))/RelaxTime !f(:,i,j) = CoefRelax*f_eq(:,i,j) + (1d0-CoefRelax)*f(:,i,j) end do end do end subroutine collide !--- ! stream step !--- subroutine stream(f) use SimulationParameter implicit none real(8),intent(inout) :: f(First:Last,1:Nx,1:Ny) integer :: i,j do j=1,Ny do i=Nx,2,-1 !RIGHT TO LEFT f(Right,i,j)=f(Right,i-1,j) end do do i=1,Nx-1 !LEFT TO RIGHT f(Left,i,j)=f(Left,i+1,j) end do end do do j=Ny,2,-1 !TOP TO BOTTOM do i=1,Nx f(Up,i,j)=f(Up,i,j-1) end do do i=Nx,2,-1 f(UpRight,i,j)=f(UpRight,i-1,j-1) end do do i=1,Nx-1 f(UpLeft,i,j)=f(UpLeft,i+1,j-1) end do end do do j=1,Ny-1 !BOTTOM TO TOP do i=1,Nx f(Down,i,j)=f(Down,i,j+1) end do do i=1,Nx-1 f(DownLeft,i,j)=f(DownLeft,i+1,j+1) end do do i=Nx,2,-1 f(DownRight,i,j)=f(DownRight,i-1,j+1) end do end do end subroutine stream !--- ! bounce-back on west, east, and south, and Zou/He boundary on upper !--- subroutine imposeBoundayCondition(f) use SimulationParameter implicit none real(8),intent(inout) :: f(First:Last,1:Nx,1:Ny) integer :: i,j real(8) :: dens_wall real(8) :: f_boundary, f_exterior do j=1,Ny !bounce back on west boundary f( Right, 1,j) = f(Opposite( Right), 1,j) f( UpRight, 1,j) = f(Opposite( UpRight), 1,j) f(DownRight, 1,j) = f(Opposite(DownRight), 1,j) !bounce back on east boundary f( Left ,Nx,j) = f(Opposite( Left ),Nx,j) f(DownLeft ,Nx,j) = f(Opposite(DownLeft ),Nx,j) f( UpLeft ,Nx,j) = f(Opposite( UpLeft ),Nx,j) end do !bounce back on south boundary do i=1,Nx f(Up ,i,1)=f(Opposite(Up ),i,1) f(UpRight,i,1)=f(Opposite(UpRight),i,1) f(UpLeft ,i,1)=f(Opposite(UpLeft ),i,1) end do !moving wall, north boundary do i=2,Nx-1 f_boundary = f(Center,i,Ny)+f( Right,i,Ny)+f( Left,i,Ny) f_exterior = f(Up ,i,Ny)+f(UpRight,i,Ny)+f(UpLeft,i,Ny) dens_wall = f_boundary + 2d0*f_exterior f(Down ,i,Ny)=f(Opposite(Down ),i,Ny) f(DownRight,i,Ny)=f(Opposite(DownRight),i,Ny) + dens_wall*Uwall/6.0 f(DownLeft ,i,Ny)=f(Opposite(DownLeft ),i,Ny) - dens_wall*Uwall/6.0 end do end subroutine imposeBoundayCondition end module D2Q9Model |
lbm_cavity.f90
файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | program LBM_Cavity use SimulationParameter use D2Q9Model implicit none real(8),allocatable :: velx(:,:) real(8),allocatable :: vely(:,:) real(8),allocatable :: dens(:,:) real(8),allocatable :: f (:,:,:) real(8),allocatable :: f_eq(:,:,:) integer :: n allocate( velx(1:Nx,1:Ny)) allocate( vely(1:Nx,1:Ny)) allocate( dens(1:Nx,1:Ny)) allocate(f (First:Last,1:Nx,1:Ny)) allocate(f_eq(First:Last,1:Nx,1:Ny)) call computeIntialMacroQuantities(velx,vely,dens) do n=1,Nt !print *,n call computeLocalEquilibriumFunction(f_eq,velx,vely,dens) call collide(f,f_eq) call stream(f) call imposeBoundayCondition(f) call computeMacroQuantities(f,velx,vely,dens) end do !call outputVelocity(velx,vely,n) deallocate(f ) deallocate(f_eq) deallocate(velx) deallocate(vely) deallocate(dens) end program LBM_Cavity !--- ! output macroscopic velocity !--- subroutine outputVelocity(velx,vely,n) use SimulationParameter implicit none real(8),intent(inout) :: velx(1:Nx,1:Ny) real(8),intent(inout) :: vely(1:Nx,1:Ny) integer,intent(in) :: n character(8) :: step integer :: i,j write(step,'(I8.8)') n open(unit = 11, file = "velocity"//trim(step)//".txt", action="write") do j=1,Ny do i=1,Nx write(11,*) i,j,velx(i,j),vely(i,j) end do end do close(11) end subroutine outputVelocity |
Дээрх гурван
тусдаа файлыг хөрвүүлэхдээ –с сонголттойгоор хөрвүүлье. Энэ нь нэгтгэлийн
дараагаар файл бүрийг обьект файлд хадгална.
} $
pgf90 -c module_SimulationParameter.f90
} $
pgf90 -c module_D2Q9Model.f90
} $
pgf90 -c lbm_cavity.f90
Ингээд обьект
файлыг хайвал
} $
pgf90 -o lbm_cavity *.o
Гарч ирсэн файлыг
бодуулж үр дүнг гаргана.
Торны хэмжээнүүдийг
өөрчилөхөд дараах хугацааг тооцоонд зарцуулсан байна.
} 512×512 52ms/step
} 1024×1024 214ms/step
} 2048×2048 900ms/step
Ингээд параллелиар
бичигдсэн кодыг авч үзье. Энд мөн 4 код багтана. Шинээр GPU параметрийн нэг файл нэмэгдсэн байна.
module_SimulationParameter.f90
|
Параметрт өөрчлөгдөх зүйл
бараг үгүй. Шинээр тайвшралтын параметрийг оруулж өгсөн байна.
|
module_D2Q9Model.cuf
|
Блок, треадуудыг ашиглан do
гогцоонуудыг алгассан байна. Түр
түгэлийн функцуудын хэрэглээ нэмэгдсэн байна.
|
lbm_cavity.cuf
|
Шинээр нэг түгэлтийн
функцын бүрдэл нэмэгдэж зарлагдах ба энэ нь мөргөлдөөнөөс бусад үед
хэрэглэгдэх ба блок хоорондын мэдээллийг солилцоход хэрэглэгдэнэ. Мөн зарим
тогтмолуудыг тогтмол санах ойд хийснээр хугацаа хожих боломжыг олгоно.
Мөргөлдөөн болон тэнцвэрт түгэлтийн функцыг нэгтгэсэнээр овоо цаг хугацаа
хэмнэнэ. Мөн хэмжигдэхүүнүүдийн бүрдэлийн инпексүүдийг сольсоноор овоо
хугацаа хэмнэнэ. Жишээ нь f(k,I,j)àf(I,j,k)
|
module_GPUParameter.cuf
|
GPU CUDA фортран
кодууд
module_SimulationParameter.f90 файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | module SimulationParameter implicit none integer,parameter :: Nt = 1 real(8),parameter :: Re = 1000d0 integer,parameter :: NumCell_x = 2048 integer,parameter :: NumCell_y = NumCell_x integer,parameter :: Nx = NumCell_x integer,parameter :: Ny = NumCell_y real(8),parameter :: dx = 1d0/dble(NumCell_x) real(8),parameter :: Uwall = 0.5d0 real(8),parameter :: dt = Uwall*dx real(8),parameter :: KineticViscosity = Uwall/dx/Re real(8),parameter :: RelaxTime = 3d0*KineticViscosity + 0.5d0 real(8),parameter :: CoefRelax = 1d0/(3d0*KineticViscosity + 0.5d0) end module SimulationParameter |
module_D2Q9Model.cuf файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 | module D2Q9Model implicit none integer,parameter :: NumParticles = 9 integer,parameter :: Center = 0 integer,parameter :: Right = 1 integer,parameter :: Up = 2 integer,parameter :: Left = 3 integer,parameter :: Down = 4 integer,parameter :: UpRight = 5 integer,parameter :: UpLeft = 6 integer,parameter :: DownLeft = 7 integer,parameter :: DownRight = 8 integer,parameter :: First = Center integer,parameter :: Last = DownRight real(8),parameter :: Weight(First:Last) & =(/ 4d0/ 9d0, & 1d0/ 9d0, 1d0/ 9d0, 1d0/ 9d0, 1d0/ 9d0,& 1d0/36d0, 1d0/36d0, 1d0/36d0, 1d0/36d0 & /) integer,parameter :: ConvVelx(First:Last) = (/ 0, 1, 0,-1, 0, 1,-1,-1, 1 /) integer,parameter :: ConvVely(First:Last) = (/ 0, 0, 1, 0,-1, 1, 1,-1,-1 /) integer,parameter :: Opposite(First:Last) & = (/ Center,& Left, Down, Right, Up,& DownLeft, DownRight,UpRight,UpLeft/) real(8),constant :: cWeight(First:Last) integer,constant :: cConvVelx(First:Last) integer,constant :: cConvVely(First:Last) integer,constant :: cOpposite(First:Last) contains !--- ! initialize macroscopic velocity and density !--- attributes(global) subroutine computeIntialMacroQuantities(velx,vely,dens) use SimulationParameter implicit none real(8),intent(inout),device :: velx(Nx,Ny) real(8),intent(inout),device :: vely(Nx,Ny) real(8),intent(inout),device :: dens(Nx,Ny) integer :: i,j i = (blockIdx%x-1)*blockDim%x + threadIdx%x j = (blockIdx%y-1)*blockDim%y + threadIdx%y velx(i,j) = 0d0 vely(i,j) = 0d0 dens(i,j) = 1d0 if (2<=i.and.i<=Nx-1 .and. j==Ny) then velx(i,j) = Uwall end if end subroutine computeIntialMacroQuantities !--- ! compute macroscopic velocity and density from distribution function !--- attributes(global) subroutine computeMacroQuantities(f,velx,vely,dens) use SimulationParameter implicit none real(8),intent(in) ,device :: f(First:Last,1:Nx,1:Ny) real(8),intent(inout),device :: velx(1:Nx,1:Ny) real(8),intent(inout),device :: vely(1:Nx,1:Ny) real(8),intent(inout),device :: dens(1:Nx,1:Ny) integer :: i,j real(8) :: f_boundary, f_exterior i = (blockIdx%x-1)*blockDim%x + threadIdx%x j = (blockIdx%y-1)*blockDim%y + threadIdx%y dens(i,j) = f(Center ,i,j)& +f(Right ,i,j)& +f(Up ,i,j)& +f(Left ,i,j)& +f(Down ,i,j)& +f(UpRight ,i,j)& +f(UpLeft ,i,j)& +f(DownLeft ,i,j)& +f(DownRight,i,j) if (2<=i.and.i<=Nx-1 .and. j==Ny) then f_boundary = f(Center,i,j)+f( Right,i,j)+f( Left,i,j) f_exterior = f(Up ,i,j)+f(UpRight,i,j)+f(UpLeft,i,j) dens(i,j) = f_boundary + 2d0*f_exterior end if if (2<=i.and.i<=Nx-1 .and. 2<=j.and.j<=Ny-1) then velx(i,j) = ( f(Center ,i,j)*cConvVelx(Center )& +f(Right ,i,j)*cConvVelx(Right )& +f(Up ,i,j)*cConvVelx(Up )& +f(Left ,i,j)*cConvVelx(Left )& +f(Down ,i,j)*cConvVelx(Down )& +f(UpRight ,i,j)*cConvVelx(UpRight )& +f(UpLeft ,i,j)*cConvVelx(UpLeft )& +f(DownLeft ,i,j)*cConvVelx(DownLeft )& +f(DownRight,i,j)*cConvVelx(DownRight)& )/dens(i,j) vely(i,j) = ( f(Center ,i,j)*cConvVely(Center )& +f(Right ,i,j)*cConvVely(Right )& +f(Up ,i,j)*cConvVely(Up )& +f(Left ,i,j)*cConvVely(Left )& +f(Down ,i,j)*cConvVely(Down )& +f(UpRight ,i,j)*cConvVely(UpRight )& +f(UpLeft ,i,j)*cConvVely(UpLeft )& +f(DownLeft ,i,j)*cConvVely(DownLeft )& +f(DownRight,i,j)*cConvVely(DownRight)& )/dens(i,j) end if end subroutine computeMacroQuantities !--- ! compute local equilibrium distribution and collision (fused kernel) !--- attributes(global) subroutine computeLocalEquilibriumFunctionAndCollision(f,velx,vely,dens) use SimulationParameter implicit none real(8),intent(inout),device :: f(First:Last,1:Nx,1:Ny) real(8),intent(in) ,device :: velx(1:Nx,1:Ny) real(8),intent(in) ,device :: vely(1:Nx,1:Ny) real(8),intent(in) ,device :: dens(1:Nx,1:Ny) real(8) :: u,v,conv_velo,velo_square,f_eq integer :: i,j,direction i = (blockIdx%x-1)*blockDim%x + threadIdx%x j = (blockIdx%y-1)*blockDim%y + threadIdx%y u = velx(i,j) v = vely(i,j) velo_square = u*u + v*v do direction = First,Last conv_velo = u*cConvVelx(direction)& + v*cConvVely(direction) f_eq = cWeight(direction)*dens(i,j)& *(1d0 + 3d0*conv_velo + 4.5d0*conv_velo*conv_velo - 1.5d0*velo_square) f(direction,i,j) = f(direction,i,j) + (f_eq-f(direction,i,j))/RelaxTime !f(direction,i,j) = CoefRelax*f_eq + (1d0-CoefRelax)*f(direction,i,j) end do end subroutine computeLocalEquilibriumFunctionAndCollision !--- ! stream step !--- attributes(global) subroutine stream(f,f_new) use SimulationParameter implicit none real(8),intent(in) ,device :: f (First:Last,1:Nx,1:Ny) real(8),intent(inout),device :: f_new(First:Last,1:Nx,1:Ny) integer :: i,j i = (blockIdx%x-1)*blockDim%x + threadIdx%x j = (blockIdx%y-1)*blockDim%y + threadIdx%y f_new(Center,i,j) = f(Center,i,j) if (1<=i .and. i<=Nx-1) then f_new(Right,i+1,j) = f(Right,i,j) end if if (1<=j .and. j<=Ny-1) then f_new(Up,i,j+1) = f(Up,i,j) end if if (2<=i .and. i<=Nx) then f_new(Left,i-1,j) = f(Left,i,j) end if if (2<=j .and. j<=Ny) then f_new(Down,i,j-1) = f(Down,i,j) end if if (1<=i .and. i<=Nx-1 .and. 1<=j .and. j<=Ny-1) then f_new(UpRight,i+1,j+1) = f(UpRight,i,j) end if if (2<=i .and. i<=Nx .and. 1<=j .and. j<=Ny-1) then f_new(UpLeft,i-1,j+1) = f(UpLeft,i,j) end if if (2<=i .and. i<=Nx .and. 2<=j .and. j<=Ny) then f_new(DownLeft ,i-1,j-1) = f(DownLeft ,i,j) end if if (1<=i .and. i<=Nx-1 .and. 2<=j .and. j<=Ny) then f_new(DownRight,i+1,j-1) = f(DownRight,i,j) end if end subroutine stream !--- ! bounce-back on south, and Zou/He boundary on upper !--- attributes(global) subroutine imposeBoundayCondition_x(f) use SimulationParameter implicit none real(8),intent(inout),device :: f(First:Last,1:Nx,1:Ny) integer :: i real(8) :: dens_wall real(8) :: f_boundary, f_exterior i = (blockIdx%x-1)*blockDim%x + threadIdx%x !bounce back on south boundary f(Up ,i,1)=f(cOpposite(Up ),i,1) f(UpRight,i,1)=f(cOpposite(UpRight),i,1) f(UpLeft ,i,1)=f(cOpposite(UpLeft ),i,1) !moving wall, north boundary if (2<=i.and.i<=Nx-1) then f_boundary = f(Center,i,Ny)+f( Right,i,Ny)+f( Left,i,Ny) f_exterior = f(Up ,i,Ny)+f(UpRight,i,Ny)+f(UpLeft,i,Ny) dens_wall = f_boundary + 2d0*f_exterior f(Down ,i,Ny)=f(cOpposite(Down ),i,Ny) f(DownRight,i,Ny)=f(cOpposite(DownRight),i,Ny) + dens_wall*Uwall/6.0 f(DownLeft ,i,Ny)=f(cOpposite(DownLeft ),i,Ny) - dens_wall*Uwall/6.0 end if end subroutine imposeBoundayCondition_x !--- ! bounce-back on west and east !--- attributes(global) subroutine imposeBoundayCondition_y(f) use SimulationParameter implicit none real(8),intent(inout),device :: f(First:Last,1:Nx,1:Ny) integer :: j j = (blockIdx%y-1)*blockDim%y + threadIdx%y !bounce back on west boundary f( Right, 1,j) = f(cOpposite( Right), 1,j) f( UpRight, 1,j) = f(cOpposite( UpRight), 1,j) f(DownRight, 1,j) = f(cOpposite(DownRight), 1,j) !bounce back on east boundary f( Left ,Nx,j) = f(cOpposite( Left ),Nx,j) f(DownLeft ,Nx,j) = f(cOpposite(DownLeft ),Nx,j) f( UpLeft ,Nx,j) = f(cOpposite( UpLeft ),Nx,j) end subroutine imposeBoundayCondition_y end module D2Q9Model |
lbm_cavity.cuf файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | program LBM_Cavity use cudafor use SimulationParameter use D2Q9Model use GPUParameter implicit none real(8),allocatable,device :: velx(:,:) real(8),allocatable,device :: vely(:,:) real(8),allocatable,device :: dens(:,:) real(8),allocatable,device :: f (:,:,:) real(8),allocatable,device :: f_new(:,:,:) integer :: n,stat stat = cudaSetDevice(3) allocate( velx(1:Nx,1:Ny)) allocate( vely(1:Nx,1:Ny)) allocate( dens(1:Nx,1:Ny)) allocate(f (First:Last,1:Nx,1:Ny));f =0d0 allocate(f_new(First:Last,1:Nx,1:Ny));f_new=0d0 cWeight =Weight cConvVelx=ConvVelx cConvVely=ConvVely cOpposite=Opposite call computeIntialMacroQuantities<<<Block,Thread>>>(velx,vely,dens) do n=1,Nt !print *,n call computeLocalEquilibriumFunctionAndCollision<<<Block,Thread>>>(f,velx,vely,dens) call stream<<<Block,Thread>>>(f,f_new) call imposeBoundayCondition_x<<<BlockBCx,ThreadBCx>>>(f_new) call imposeBoundayCondition_y<<<BlockBCy,ThreadBCy>>>(f_new) call computeMacroQuantities<<<Block,Thread>>>(f_new,velx,vely,dens) f = f_new end do !call outputVelocity(velx,vely) deallocate(f ) deallocate(f_new) deallocate(velx ) deallocate(vely ) deallocate(dens ) end program LBM_Cavity !--- ! output macroscopic velocity !--- subroutine outputVelocity(velx,vely) use SimulationParameter implicit none real(8),intent(inout),device :: velx(1:Nx,1:Ny) real(8),intent(inout),device :: vely(1:Nx,1:Ny) integer :: i,j real(8),allocatable :: host_velx(:,:) real(8),allocatable :: host_vely(:,:) allocate(host_velx(Nx,Ny));host_velx = velx allocate(host_vely(Nx,Ny));host_vely = vely open(unit = 11, file = "velocity.txt", action="write") do j=1,Ny do i=1,Nx write(11,*) i,j,host_velx(i,j),host_vely(i,j) end do end do close(11) deallocate(host_velx) deallocate(host_vely) end subroutine outputVelocity |
module_GPUParameter.cuf
файл
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | module GPUParameter use cudafor use SimulationParameter,only:Nx,Ny implicit none integer,parameter :: num_Thread = 256 integer,parameter :: Thread_x = min(Nx,num_Thread) integer,parameter :: Thread_y = 1 integer,parameter :: Block_x = Nx/Thread_x integer,parameter :: Block_y = Ny/Thread_y type(dim3),parameter :: Thread = dim3(Thread_x, Thread_y, 1) type(dim3),parameter :: Block = dim3( Block_x, Block_y, 1) integer,parameter :: ThreadBCx_x = min(Nx,num_Thread) integer,parameter :: ThreadBCx_y = 1 integer,parameter :: BlockBCx_x = Nx/ThreadBCx_x integer,parameter :: BlockBCx_y = Ny/ThreadBCx_y type(dim3),parameter :: ThreadBCx = dim3(ThreadBCx_x, ThreadBCx_y, 1) type(dim3),parameter :: BlockBCx = dim3( BlockBCx_x, BlockBCx_y, 1) integer,parameter :: ThreadBCy_x = 1 integer,parameter :: ThreadBCy_y = min(Ny,num_Thread) integer,parameter :: BlockBCy_x = Nx/ThreadBCy_x integer,parameter :: BlockBCy_y = Ny/ThreadBCy_y type(dim3),parameter :: ThreadBCy = dim3(ThreadBCy_x, ThreadBCy_y, 1) type(dim3),parameter :: BlockBCy = dim3( BlockBCy_x, BlockBCy_y, 1) end module GPUParameter |
Нэг зангилаан
дээр 9 чиглэлд түгэлтийн функц байх учир 1 зангилааг 1 треад гэж авч үзэж
болно. Ингэхэд урсах алхамыг шийдвэрлэхэд асуудал үүснэ. Жишээ нь 33-р треадын
хувьд түүний хөршүүдээс түгэлтийн функцаа авах шаардлагатай болно.
f(1,33,1)=f(1,32,1) – 32-р треадын хувьд
f(1,34,1)=f(1,33,1) – 33-р трайдын хувьд
Харин түр ТФ-ын
бүрдэлийг хэрэглэвэл
f_new(1,33,1)=f(1,32,1) – 32-р треадын хувьд
f_new(1,34,1)=f(1,33,1) – 33-р треадын хувьд


Дээрх цуваа код
нь naive, харин GPU код нь kernel fusion юм.
Цаашид уншиж
судлах боломжтой гарын авлага
Learning materials by Prof. Degawa Tomohiro
Дээрхи тайлбарлал болон түүнд орсон кодууд бүх хамаатай зүйлс 2016 оны 1 сарын 13-нд НТС-ын Мэдээлэл процессын төвөөс зохион байгуулсан ээлжит семинарын материал дээр үндэслэсэн юм.
I really appreciated Prof.Degawa Tomohiro who had lectured to only me for one time slot to acquire basics of GPU and application of GPGPU.
I really appreciated Prof.Degawa Tomohiro who had lectured to only me for one time slot to acquire basics of GPU and application of GPGPU.








Өндөр бүтээмжтй тооцооллын ач холбогдлын тухай бичлэгүүд. 15th conference on Super Computing
Супер компьютер - уур амьсгал, байгалийн ухааны загварчилал, тооцоололд
No comments:
Post a Comment